
This is chapter 11 of a multi-part series on writing a RISC-V OS in Rust.
Table of Contents → Chapter 10 → (Chapter 11)
Userspace Processes
Resources and References
The ELF standard can be found here: ELF File Format (PDF).
Introduction
This is the moment we've all been waiting for. Ten chapters of setup have led us to this moment--to finally be able to load a process from the disk and run it. The file format for executables is called ELF (executable and linkable format). I will go into some detail about it, but there are plenty of avenues you can explore with this one file type.
The ELF File Format
The executable and linkable format (ELF) is a widely used file format. If you've used Linux, you no doubt have seen it or the effects of it. This file format contains an ELF header, followed by program headers. Each time, we're telling the OS where the linker has mapped the executable sections. If you don't remember, we have a .text section for CPU instructions, .rodata for global constants, .data for global initialized variables, and .bss section for global uninitialized variables. In the ELF format, the compiler decides where to put these. Also, since we're using virtual memory addresses, the ELF header specifies the entry point, which is what we'll put in the program counter when scheduling a process for the first time.
[joke]My handwriting hasn't improved since I was 4[/joke]
Let's look at some Rust structures that will help us. These are in elf.rs.
#[repr(C)]
pub struct Header {
pub magic: u32,
pub bitsize: u8,
pub endian: u8,
pub ident_abi_version: u8,
pub target_platform: u8,
pub abi_version: u8,
pub padding: [u8; 7],
pub obj_type: u16,
pub machine: u16, // 0xf3 for RISC-V
pub version: u32,
pub entry_addr: usize,
pub phoff: usize,
pub shoff: usize,
pub flags: u32,
pub ehsize: u16,
pub phentsize: u16,
pub phnum: u16,
pub shentsize: u16,
pub shnum: u16,
pub shstrndx: u16,
}
All ELF files start with this ELF Header structure. The very top is 0x7f followed by capital ELF, which is 0x7f 0x45 0x4c and 0x46 as you can see below. I took a simple hexdump of the ls (list) command. You can see sure as sh*t that the magic is right there.
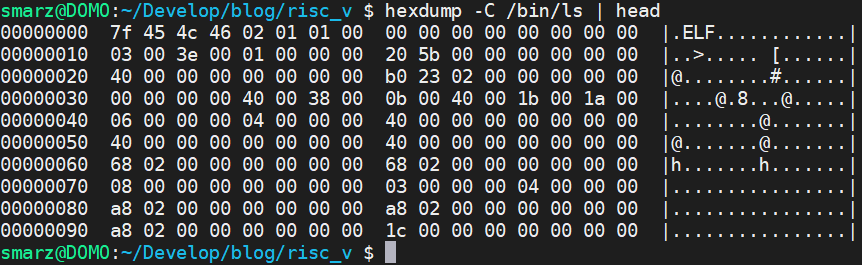
The rest of the fields will tell us for which architecture this ELF file was made. RISC-V has reserved 0xf3 as its machine type. So, when we load an ELF from the disk, we must make sure it's for the correct architecture. You'll also notice that entry_addr is up there too. This is a virtual memory address where _start begins. Our _start just simply calls main and then when main returns, it calls the exit system call. This is how most programs actually work, but they do a much more rigorous job including getting command line arguments and so forth. Right now, we don't have those.
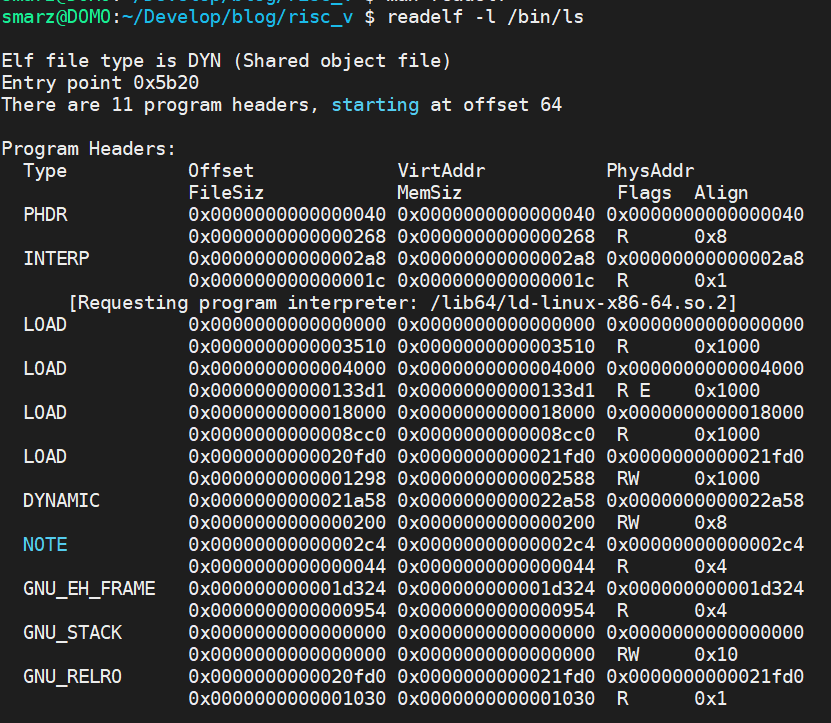
The field that we need to know is the phoff field which specifies the program headers' offset. The program headers is a table of one or more program sections. I took a snapshot of ls (again) and the program headers. You can do the same using readelf -l /bin/ls. The code below shows how I read the ELF header in Rust.
let elf_hdr;
unsafe {
elf_hdr = (buffer.get() as *const elf::Header).as_ref().unwrap();
}
if elf_hdr.magic != elf::MAGIC {
println!("ELF magic didn't match.");
return;
}
if elf_hdr.machine != elf::MACHINE_RISCV {
println!("ELF loaded is not RISC-V.");
return;
}
if elf_hdr.obj_type != elf::TYPE_EXEC {
println!("ELF is not an executable.");
return;
}
You can see that now we're at the program headers, which I took a snapshot of for /bin/ls.
The program headers have the following structure in Rust.
#[repr(C)]
pub struct ProgramHeader {
pub seg_type: u32,
pub flags: u32,
pub off: usize,
pub vaddr: usize,
pub paddr: usize,
pub filesz: usize,
pub memsz: usize,
pub align: usize,
}
/bin/ls uses shared libraries, but we're not that good, yet. So, the only program headers we care about are the ones shown by LOAD. These are the sections that we need to load into memory for our static binaries. In the ProgramHeader structure, we need seg_type to be LOAD. The flags tell us how to protect the virtual memory. There are three flags EXECUTE (1), WRITE (2), and READ (4). We also need the off (offset), which tells us where in the ELF file that section to load into the program memory is contained. Finally, the vaddr is what we need to point the MMU to where we loaded this section into memory. You can see how I did this in test.rs in the test_elf() function.
for i in 0..elf_hdr.phnum as usize {
let ph = ph_tab.add(i).as_ref().unwrap();
if ph.seg_type != elf::PH_SEG_TYPE_LOAD {
continue;
}
if ph.memsz == 0 {
continue;
}
memcpy(program_mem.add(ph.off), buffer.get().add(ph.off), ph.memsz);
let mut bits = EntryBits::User.val();
if ph.flags & elf::PROG_EXECUTE != 0 {
bits |= EntryBits::Execute.val();
}
if ph.flags & elf::PROG_READ != 0 {
bits |= EntryBits::Read.val();
}
if ph.flags & elf::PROG_WRITE != 0 {
bits |= EntryBits::Write.val();
}
let pages = (ph.memsz + PAGE_SIZE) / PAGE_SIZE;
for i in 0..pages {
let vaddr = ph.vaddr + i * PAGE_SIZE;
let paddr = program_mem as usize + ph.off + i * PAGE_SIZE;
map(table, vaddr, paddr, bits, 0);
}
}
All I do with the code above is enumerate all of the program headers. The ELF header tells us how many there are via the phnum field. We then check the segment type to see if it is LOAD. If it isn't, we skip it. Then, we check to see if that segment actually contains anything. If not, there's no use in loading it. Then, we copy what we read from the filesystem (buffer) into the process' memory (program_mem). Since these are virtual memory address, the rest of the code determines how we should map the pages.
Executing the Process
We need to map a few things, including the stack and the program. Also, don't forget to set the program counter to the entry_addr!
(*my_proc.frame).pc = elf_hdr.entry_addr;
(*my_proc.frame).regs[2] = STACK_ADDR as usize + STACK_PAGES * PAGE_SIZE;
(*my_proc.frame).mode = CpuMode::User as usize;
(*my_proc.frame).pid = my_proc.pid as usize;
(*my_proc.frame).satp = build_satp(SatpMode::Sv39, my_proc.pid as usize, my_proc.root as usize);
In here, regs[2] is the stack pointer (SP). This must be valid and mapped, otherwise the process will immediately page fault. Now that everything is set up, our last bit of execution is to add it to the process list. When the scheduler gets around to it, it will run our newly minted process!
if let Some(mut pl) = unsafe { PROCESS_LIST.take() } {
println!(
"Added user process to the scheduler...get ready \
for take-off!"
);
pl.push_back(my_proc);
unsafe {
PROCESS_LIST.replace(pl);
}
}
else {
println!("Unable to spawn process.");
}
Writing Userspace Programs
We don't have a C library, yet. However, I'm making the OS come close to the newlib, which is a small C-library mainly for embedded systems. For now, I made a small library called startlib that will get us off the ground, and I copied printf into it.
.section .text.init
.global _start
_start:
call main
li a0, 93
j make_syscall
The _start is a special label that the compiler will use as the entry point address. Recall that we set this in the program counter when we made a new process. After main returns, we schedule a system call number 93, which is the exit system call. All this system call does is deschedule the process and free all of its resources.
There are other utilities, including printf in our small library, but let's make a simple program to see if we can get it to work. To be more robust, I'm going to stretch all of our available sections to see if they load properly.
#include <printf.h>
const int SIZE = 1000;
int myarray[SIZE];
int another_array[5] = {1, 2, 3, 4, 5};
int main()
{
printf("I'm a C++ program, and I'm running in user space. How about a big, Hello World\n");
printf("My array is at 0x%p\n", myarray);
printf("I'm going to start crunching some numbers, so gimme a minute.\n");
for (int i = 0;i < SIZE;i++) {
myarray[i] = another_array[i % 5];
}
for (int i = 0;i < 100000000;i++) {
myarray[i % SIZE] += 1;
}
printf("Ok, I'm done crunching. Wanna see myarray[0]? It's %d\n", myarray[0]);
return 0;
}
The program doesn't really do anything useful, but it will see if system calls work as well as context switching. On QEMU, this takes around 5 to 8 seconds to run on my machine at home.
We then compile this using our C++ toolchain (if you have one). riscv64-unknown-elf-g++ -Wall -O0 -ffreestanding -nostartfiles -nostdlib -static -march=rv64g -mabi=lp64d -I./startlib -L./startlib -o helloworld.elf helloworld.cpp -lstart
If you don't have a toolchain, you can download my program here: helloworld.elf. This requires that you have the systems calls identical to mine since it goes by a system call number.
Uploading the Program
We can use Linux to upload our elf file.
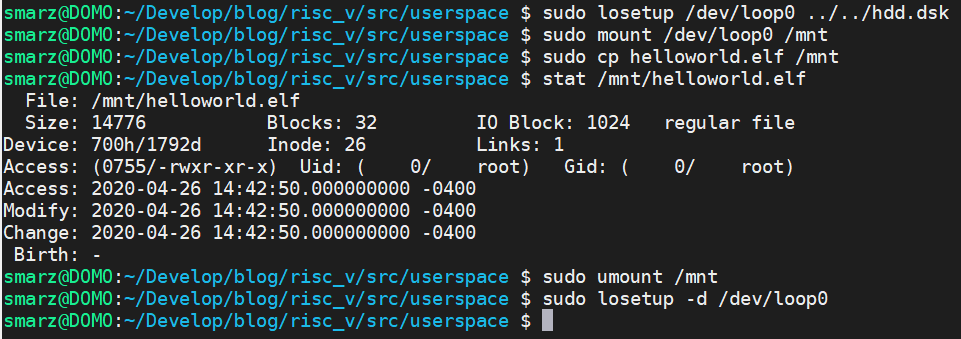
Take note of the inode number (26) and the file size (14776). Yours might be different, so make sure you stat it! Modify test.rs and put your inode and file size at the top.
let files_inode = 26u32; // Change to yours!
let files_size = 14776; // Change to yours!
let bytes_to_read = 1024 * 50;
let mut buffer = BlockBuffer::new(bytes_to_read);
let bytes_read = syscall_fs_read(
8,
files_inode,
buffer.get_mut(),
bytes_to_read as u32,
0,
);
if bytes_read != files_size {
println!(
"Unable to load program at inode {}, which should \
be {} bytes, got {}",
files_inode, files_size, bytes_read
);
return;
}
This will use our filesystem read call to read the given inode into memory. Then we double check that the size is exactly what stat said it was. Then we begin the ELF loading process as I previously discussed.
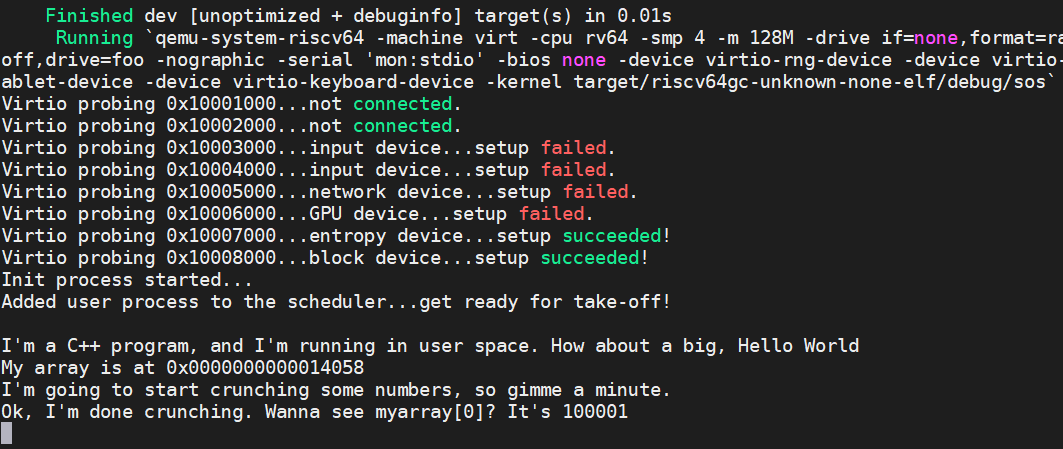
From here, when you cargo run your OS, you should see the following:
Let's take a look again at what is doing this:
#include <printf.h>
const int SIZE = 1000;
int myarray[SIZE];
int another_array[5] = {1, 2, 3, 4, 5};
int main()
{
printf("I'm a C++ program, and I'm running in user space. How about a big, Hello World\n");
printf("My array is at 0x%p\n", myarray);
printf("I'm going to start crunching some numbers, so gimme a minute.\n");
for (int i = 0;i < SIZE;i++) {
myarray[i] = another_array[i % 5];
}
for (int i = 0;i < 100000000;i++) {
myarray[i % SIZE] += 1;
}
printf("Ok, I'm done crunching. Wanna see myarray[0]? It's %d\n", myarray[0]);
return 0;
}
Well, ain't that something?! That's what I saw print to the screen! Notice that myarray[0] gets 100001. At the beginning, we put the value 1 into myarray[0], then every 1000 of 100000000, we put one more into myarray[0], which in total is 100001. So, yep, our sections appear to be functioning properly!
Verify
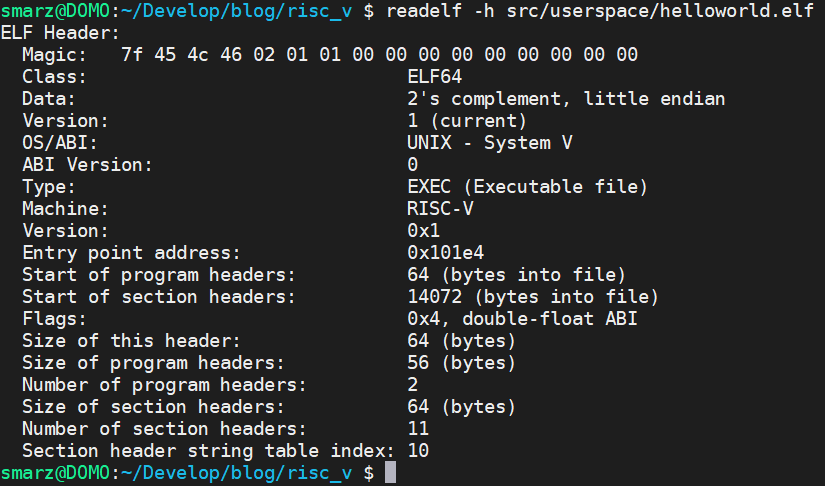
Let's examine our helloworld.elf file to see what we did in Rust. Let's first examine the ELF header. You will see that our entry point 0x101e4 is what we put into PC (you can println! this out to verify).
And now the program headers. This caused me to write several bugs when I first examined the program headers. Notice that the .text, .rodata, and .eh_frame are put into the first header with read and execute permissions. Also notice that 0x303c and 0x3040 (end of PH 0 and the start of PH 1) overlap physical pages (but not virtual pages). I don't like this. The .rodata should not be executable, but it is because it's in the same physical and virtual page as the .text section.
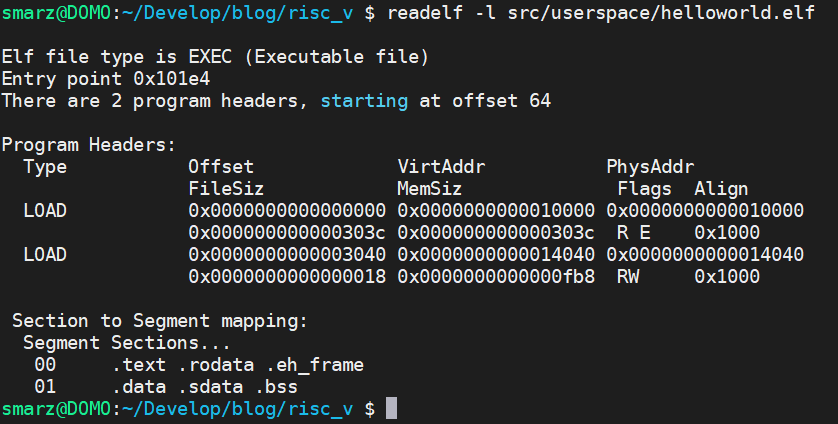
Look at that. Our ELF header shows exactly what we verified in our OS, and the program headers are about right, too. In Linux, the only file type that really matters is ELF. Everything else is left up to whatever helper program it needs.
Conclusion
Welcome to the conclusion of this OS tutorial. To round out your operating system, you will need to add system calls for read, write, readdir, and so forth. I put a list from libgloss in syscall.rs (at the bottom) so you know what system calls libgloss contains. The ultimate test will be compiling gcc into your filesystem and executing it from there. Also, we need to have a traversal function to traverse the directory structure by name. Currently, we're locating by inode number, which isn't good. However, you get to see all of the useful parts of an OS.
This finishes the tutorial, however I will be adding things to our OS. I plan on graphics and networking, but that stretches the scope of the tutorial, so I will put them in their own blog posts.
Congratulations, you now have an OS that runs processes! As always, you can find the OS and all of its updates at my GitHub repository: https://github.com/sgmarz/osblog.
Table of Contents → Chapter 10 → (Chapter 11)