
This is chapter 4 of a multi-part series on writing a RISC-V OS in Rust.
Table of Contents → Chapter 3.2 → (Chapter 4) → Chapter 5
Handling Interrupts and Traps
Overview
Wouldn't it be nice if nothing ever went wrong? Well, too bad. That ain't gonna' happen. So, we need to be ready when a problem occurs. The CPU is able to notify the kernel whenever something happens. Now, with that being said, not all notifications are bad. What about system calls? or interrupt timers? Yep, those cause the CPU to notify the kernel too!
RISC-V Interrupt System
The RISC-V system uses a single function pointer to a physical address in the kernel. Whenever something happens, the CPU will switch to machine mode and jump to the function. In RISC-V, we have two special CS (control and status) registers that control this CPU communication.
The first register is the mtvec register, which stands for Machine Trap Vector. A vector is a function pointer. Whenever something happens, the CPU will "call" the function given by this register.
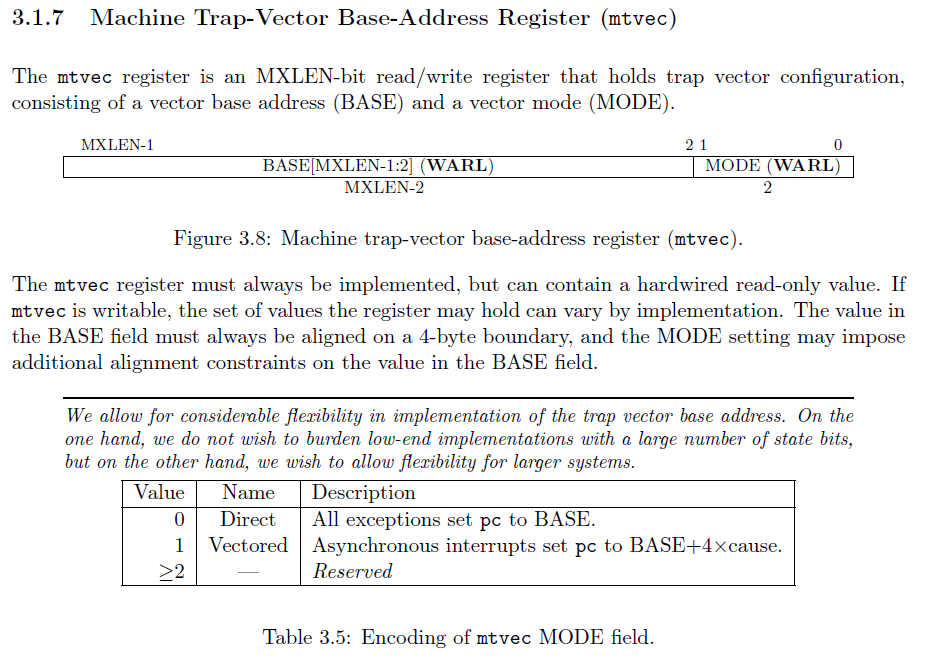
The mtvec register has two different fields. The BASE, which is the function's address, and then MODE, which determines whether we're going to use direct or vectored interrupts. We're going to use Rust's match to redirect traps. So, we need to make sure that the last two bits are 0, which means that our function's address needs to be a multiple of 4.
A direct mode mtvec means that all traps will go to the exact same function, whereas a vectored mode mtvec will go to different functions based on what caused the trap. To simplify things, I'm going to use the direct mode. Then, we can parse out the cause using Rust's match statement.
Why Did We Trap?
The mcause register (machine cause) will give you an exception code to explain, generically, what caused the trap. There are two different types: asynchronous and synchronous. An asynchronous trap means that something outside of the currently executing instruction caused the CPU to "trap". A synchronous trap means that the currently executing instruction caused the "trap".
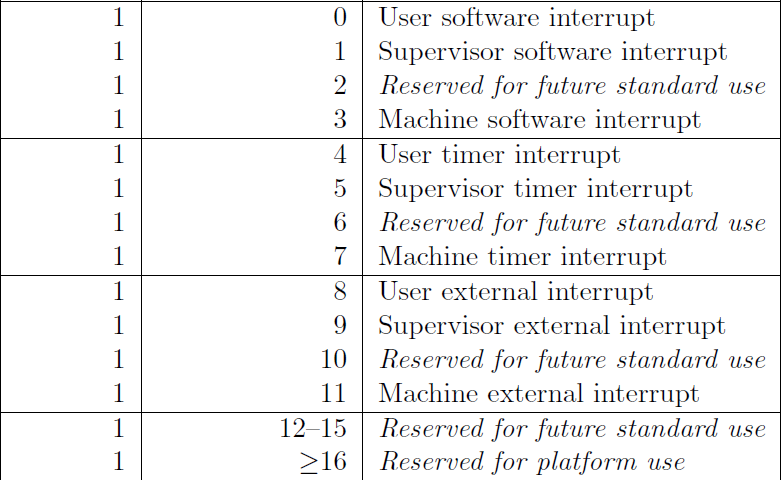
Asynchronous causes always have the most significant bit as 1.
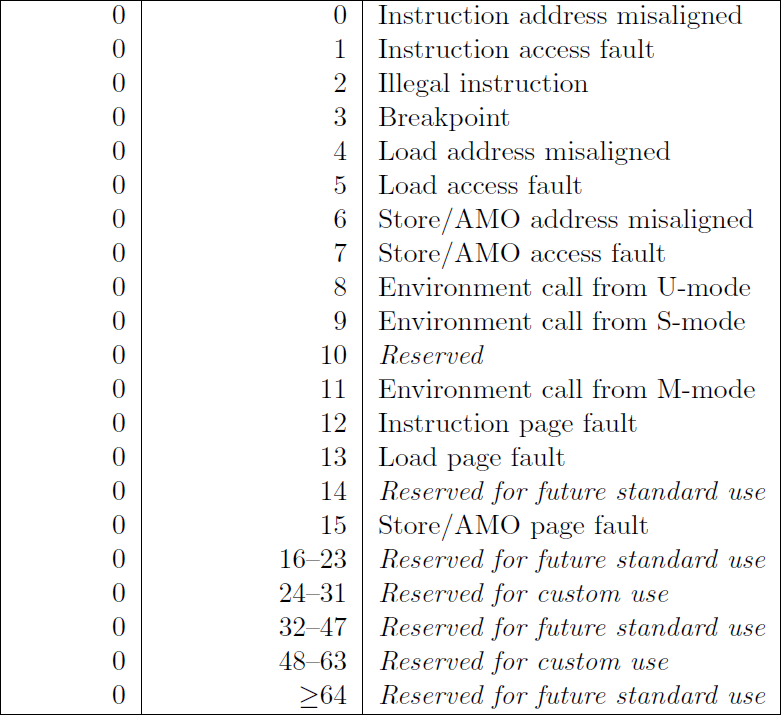
Synchronous causes always have the most significant bit as 0.
Start Easy
I have modified the boot code to start off easy. We enter Rust through kinit, which runs code in physical-memory-only, machine mode. We essentially have
free reign over our system in this function. However, the point of kinit is to get us into kmain as soon as possible. We will run the kmain function in supervisor mode, where we have virtual memory turned on for our kernel.
# We need a stack for our kernel. This symbol comes from virt.lds
la sp, _stack_end
# Setting `mstatus` register:
# 0b01 << 11: Machine's previous protection mode is 2 (MPP=2).
li t0, 0b11 << 11
csrw mstatus, t0
# Do not allow interrupts while running kinit
csrw mie, zero
# Machine's exception program counter (MEPC) is set to `kinit`.
la t1, kinit
csrw mepc, t1
# Set the return address to get us into supervisor mode
la ra, 2f
# We use mret here so that the mstatus register is properly updated.
mret
Our code sets us up for machine mode. We write zero into mie, which is the machine interrupt-enable register, to disable all interrupts. Therefore, kinit is
in machine mode, physical-memory-only, and now non-preemptible. This allows us to set up our machine without having to worry about other harts (cores) interfering with our process.
Trapping
Trapping is essentially a way for the CPU to notify your kernel. Typically, we as the os programmer tell the CPU what's going on. However, sometimes the CPU needs to let us know what's going on. It does this through a trap, as mentioned above. So, to handle traps in Rust, we need to create a new file, trap.rs.
// trap.rs
// Trap routines
// Stephen Marz
// 10 October 2019
use crate::cpu::TrapFrame;
#[no_mangle]
extern "C" fn m_trap(epc: usize,
tval: usize,
cause: usize,
hart: usize,
status: usize,
frame: &mut TrapFrame)
-> usize
{
// We're going to handle all traps in machine mode. RISC-V lets
// us delegate to supervisor mode, but switching out SATP (virtual memory)
// gets hairy.
let is_async = {
if cause >> 63 & 1 == 1 {
true
}
else {
false
}
};
// The cause contains the type of trap (sync, async) as well as the cause
// number. So, here we narrow down just the cause number.
let cause_num = cause & 0xfff;
let mut return_pc = epc;
if is_async {
// Asynchronous trap
match cause_num {
3 => {
// Machine software
println!("Machine software interrupt CPU#{}", hart);
},
7 => unsafe {
// Machine timer
let mtimecmp = 0x0200_4000 as *mut u64;
let mtime = 0x0200_bff8 as *const u64;
// The frequency given by QEMU is 10_000_000 Hz, so this sets
// the next interrupt to fire one second from now.
mtimecmp.write_volatile(mtime.read_volatile() + 10_000_000);
},
11 => {
// Machine external (interrupt from Platform Interrupt Controller (PLIC))
println!("Machine external interrupt CPU#{}", hart);
},
_ => {
panic!("Unhandled async trap CPU#{} -> {}\n", hart, cause_num);
}
}
}
else {
// Synchronous trap
match cause_num {
2 => {
// Illegal instruction
panic!("Illegal instruction CPU#{} -> 0x{:08x}: 0x{:08x}\n", hart, epc, tval);
},
8 => {
// Environment (system) call from User mode
println!("E-call from User mode! CPU#{} -> 0x{:08x}", hart, epc);
return_pc += 4;
},
9 => {
// Environment (system) call from Supervisor mode
println!("E-call from Supervisor mode! CPU#{} -> 0x{:08x}", hart, epc);
return_pc += 4;
},
11 => {
// Environment (system) call from Machine mode
panic!("E-call from Machine mode! CPU#{} -> 0x{:08x}\n", hart, epc);
},
// Page faults
12 => {
// Instruction page fault
println!("Instruction page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval);
return_pc += 4;
},
13 => {
// Load page fault
println!("Load page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval);
return_pc += 4;
},
15 => {
// Store page fault
println!("Store page fault CPU#{} -> 0x{:08x}: 0x{:08x}", hart, epc, tval);
return_pc += 4;
},
_ => {
panic!("Unhandled sync trap CPU#{} -> {}\n", hart, cause_num);
}
}
};
// Finally, return the updated program counter
return_pc
}
The code above is where we go when a trap is hit. The CPU hits a trap, refers to mtvec and then goes to the address specified in there. Notice we have to parse out the interrupt type (asynchronous vs synchronous) and then its cause.
Notice that we have three synchronous traps which are expected: 8, 9, and 11. These are "environment" calls, which are system calls. However, the cause is parsed out based on which mode we are in when the ecall instruction was made. I cause a panic! for machine mode ecalls, since we shouldn't ever get a machine mode ecall. Instead, we run the kernel in supervisor mode and user applications will enter via the u-mode ecall.
We need to keep track of our registers and so forth when we hit a trap. If we start messing with the registers, there is no way we can restart a user application. We will save this information into something called a trap frame. We will also use the mscratch register to store this information, so that it is easy to find when we hit a trap.
Trap Frame Rust Structure
#[repr(C)]
#[derive(Clone, Copy)]
pub struct TrapFrame {
pub regs: [usize; 32], // 0 - 255
pub fregs: [usize; 32], // 256 - 511
pub satp: usize, // 512 - 519
pub trap_stack: *mut u8, // 520
pub hartid: usize, // 528
}
As you can see with the structure above, we store all general purpose registers, floating point registers, the SATP (MMU), a stack to handle the trap, and the hardware thread id. The last one isn't necessary when we use only machine-mode traps. RISC-V allows us to delegate certain traps to supervisor mode. However, we haven't done this. For now, hartid is redundant since we can get the hardware thread id via csrr a0, mhartid.
You will also notice two Rust directives: #[repr(C)] and #[derive(Clone, Copy]. The first directive makes our structure follow the C-style structures. We do this because we need to know the offsets of each member when we manipulate the trap frame in assembly. Finally, the derive directive will make Rust implement the Copy and Clone traits. If we didn't use derive, we would have to do it ourselves.
Now that we have the trap frame set up, let's see how this will look in assembly:
Looking at the Assembly Trap Vector
.option norvc
m_trap_vector:
# All registers are volatile here, we need to save them
# before we do anything.
csrrw t6, mscratch, t6
# csrrw will atomically swap t6 into mscratch and the old
# value of mscratch into t6. This is nice because we just
# switched values and didn't destroy anything -- all atomically!
# in cpu.rs we have a structure of:
# 32 gp regs 0
# 32 fp regs 256
# SATP register 512
# Trap stack 520
# CPU HARTID 528
# We use t6 as the temporary register because it is the very
# bottom register (x31)
.set i, 1
.rept 30
save_gp %i
.set i, i+1
.endr
# Save the actual t6 register, which we swapped into
# mscratch
mv t5, t6
csrr t6, mscratch
save_gp 31, t5
# Restore the kernel trap frame into mscratch
csrw mscratch, t5
# Get ready to go into Rust (trap.rs)
# We don't want to write into the user's stack or whomever
# messed with us here.
csrr a0, mepc
csrr a1, mtval
csrr a2, mcause
csrr a3, mhartid
csrr a4, mstatus
mv a5, t5
ld sp, 520(a5)
call m_trap
# When we get here, we've returned from m_trap, restore registers
# and return.
# m_trap will return the return address via a0.
csrw mepc, a0
# Now load the trap frame back into t6
csrr t6, mscratch
# Restore all GP registers
.set i, 1
.rept 31
load_gp %i
.set i, i+1
.endr
# Since we ran this loop 31 times starting with i = 1,
# the last one loaded t6 back to its original value.
mret
You can see we use what are known as directives and macros, such as .set and store_gp. We use these to make our lives easier. This is essentially an assemble-time loop and will be expanded when we assemble this file.
We also specify the .option norvc which means "RISC-V compressed instructions", which is the C extension to the RISC-V ISA. This forces all instructions for the trap vector to be 32-bits a piece. This isn't that important, but when we add multiple trap vectors, we need to make sure that each vector function starts at a memory address which is a multiple of 4. This is because the mtvec register uses the last two bits to change the trapping mode between vectored and direct.
GNU Assembly Macros
The macros are defined as follows:
.altmacro
.set NUM_GP_REGS, 32 # Number of registers per context
.set NUM_FP_REGS, 32
.set REG_SIZE, 8 # Register size (in bytes)
.set MAX_CPUS, 8 # Maximum number of CPUs
# Use macros for saving and restoring multiple registers
.macro save_gp i, basereg=t6
sd x\i, ((\i)*REG_SIZE)(\basereg)
.endm
.macro load_gp i, basereg=t6
ld x\i, ((\i)*REG_SIZE)(\basereg)
.endm
.macro save_fp i, basereg=t6
fsd f\i, ((NUM_GP_REGS+(\i))*REG_SIZE)(\basereg)
.endm
.macro load_fp i, basereg=t6
fld f\i, ((NUM_GP_REGS+(\i))*REG_SIZE)(\basereg)
.endm
Reading the macros above is beyond the scope of this blog, but it is worth mentioning that we're executing one of the following instructions sd, ld, fsd, fld, and, by default, we use the t6 register. The reason I chose the t6 register is because it is register number 31. This makes it easy to keep track of when we run a loop from register 0 all the way to 31.
What Does This Do?
The trap is caused by the CPU. Each hart can take a trap, so we will need to work on mutual exclusion and deferred actions later.
You should see the following output when you run the code:
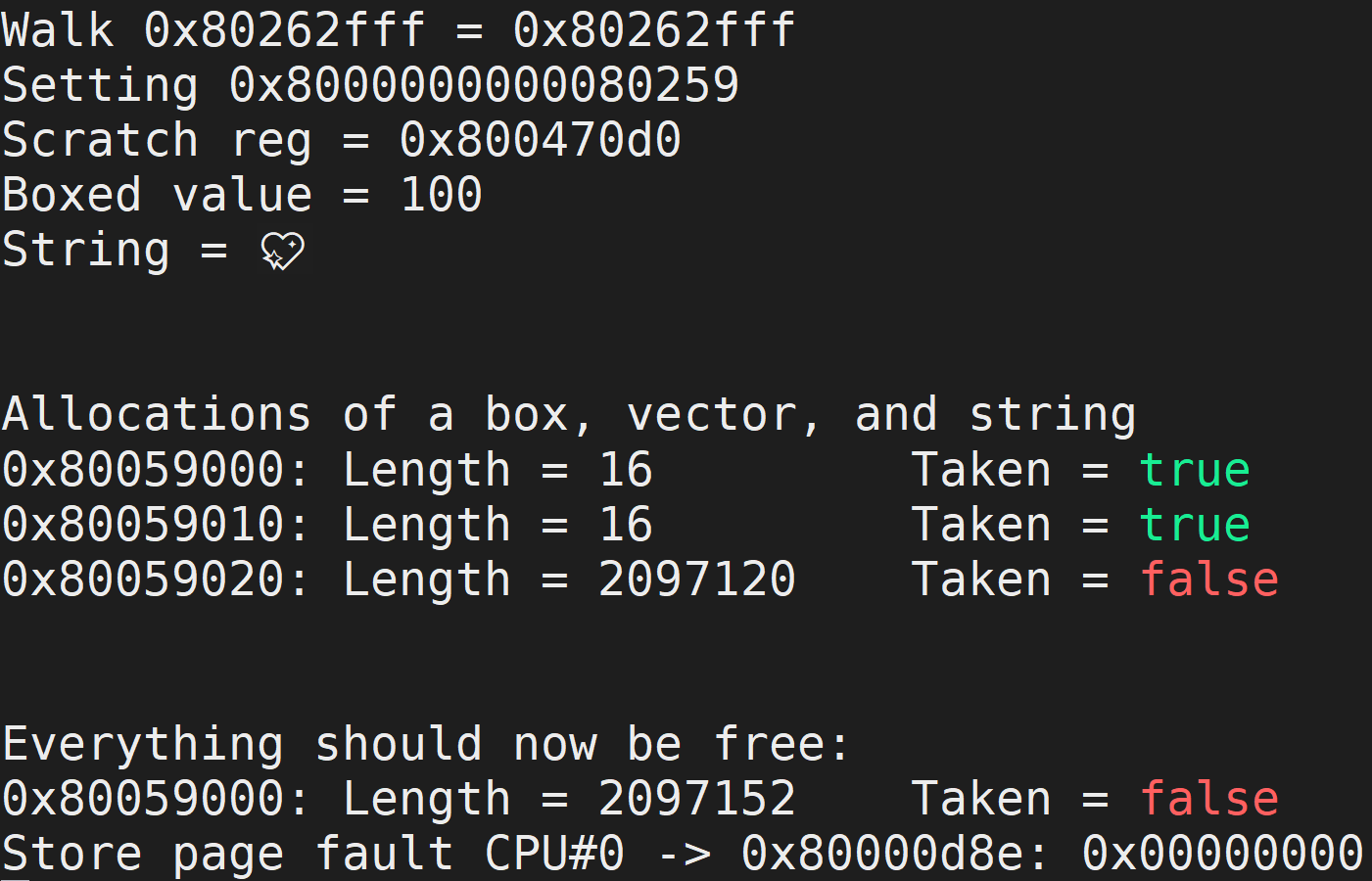
You will notice that we have a page fault at the bottom. This is intentional as I've added the following into our Rust code. This all but guarantees a page fault!
unsafe {
// Set the next machine timer to fire.
let mtimecmp = 0x0200_4000 as *mut u64;
let mtime = 0x0200_bff8 as *const u64;
// The frequency given by QEMU is 10_000_000 Hz, so this sets
// the next interrupt to fire one second from now.
mtimecmp.write_volatile(mtime.read_volatile() + 10_000_000);
// Let's cause a page fault and see what happens. This should trap
// to m_trap under trap.rs
let v = 0x0 as *mut u64;
v.write_volatile(0);
}
The first part resets the CLINT timer, which will fire off an asynchronous machine timer trap. Then, we dereference the NULL pointer, which causes our store page fault. If this was v.read_volatile(), we would get a load page fault, instead.
Table of Contents → Chapter 3.2 → (Chapter 4) → Chapter 5